
Information Extraction from long texts using ODIN
The task of my internship with LUM AI was to create the grammar and extraction filters for an ODIN-based Information Extraction system.
The documents that required extraction were technical and contract documents provided by government agencies for the construction of public projects. They covered the details of projects like rebuilding sewer lift pump stations, adding wells to landfills, and other public construction projects. The client was a construction company looking to streamline their estimate process. The goal was to have the most critical details at a glance rather than digging through these documents, which could be up to 700 pages long.
A Brief Introduction to ODIN
Odin (Open Domain INformer) is an extraction framework that operates over documents that have been tokenized, sentence-segmented, part of speech tagged, lemmatized, and named entity tagged, and dependency parsed using an NLP pipeline. For a complete introduction see the link, I’ll only include some basics in this post.
The framework is characterized by its rule-based approach. Each rule can rely on any of the underlying annotation systems or the plain text.
A simple rule might be a lemma like “bid” or a NER tag of “org”.
- name: "bid"
priority: 1
label: Bid
type: token
keep: false
example: "Bids"
pattern: |
[lemma=bid]|[lemma=proposal]
- name: "org-ner"
label: Org
priority: 1
type: token
keep: false
pattern: |
[entity=/ORG/]+
Complex rules combine several rules or the occurrence of a previous rule in a specific syntactic position.
- name: 'bid-time-event-1'
priority: 2
label: BidTime
pattern: |
trigger = [lemma=receive]|[lemma=open]
dummy_bid:Bid = (>dobj|>nsubjpass|>nsubj) (>nmod_for)?
time:Time = (>nmod_at|>nmod_to)? (>nmod_of)? (>nmod_until|>/^nmod/|>dep)? (>nummod|>compound)?
In this example, we have a ‘bid’ rule and a ‘time’ rule utilized as parts of an Event-Mention. The grammatical relationships being described here are derived from the dependency parse portion of the NLP pipeline.
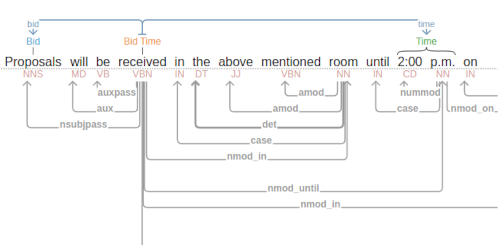
After applying the grammar (set of all rules) to the annotated document, we are left with our Mentions.
In this project, Odin Mentions are filtered and pruned into Extractions, the end product for users. The initial and main mechanism for filtering rules is a keep: flag, which defaults to True. If you are curious about seeing which of our (admittedly many) rules were reaching end users, that is the easiest way to tell.
Documents and Extractions
The documents we were processing did not follow a universal standard but came in two main types.
Type A was an expansive tome (200-700) containing many sections on various technical requirements, and a single large section covering the legal agreements between various construction companies and the government entity contracting the work.
Type B was an “Addendum” a 1-15 page document, that indicated that something had changed in the original document. A mistake or typo occurred in the original document, or some circumstance had changed. This will be important later.
From these documents, our customer wanted ten different fields extracted. - Project Name - Project Owner - Project Duration - Project Location - Bid Date - Bid Time - Engineer’s Estimate - Engineer of Record - Qualifications and Concerns - Liquidated Damages
Each of the rules in variable_grammar.yml contributes to the capture of these variables as they occur in the texts.
Variable Grammar
It would be tedious and unnecessary to cover the detail of every rule in variable_grammar.yml, so instead I will highlight the process for a few rules to give a general sense. After these explanations, any other questions should be able to be answered by examining the code.
Example 1: Regex for Dollar - Engineer’s Estimate
The Engineer’s Estimate is the Engineer of Record’s estimate for how much the project will cost overall. It shows up in a variety of different formats and needs to be differentiated from Liquidated Damages which is also a dollar amount. The two differed mainly by length.
- name: "5-8-digit-dollar"
label: Dollars
priority: 1
type: token
keep: false
example: "$1,000,000"
pattern: |
[tag=$] /\d{1,3},*\d{3},*(\d{3})*/
This rule is then combined with a setting rule that looks for phrasing we found around Engineer’s Estimates.
- name: "estimated-cost"
label: Cost
priority: 1
type: token
keep: false
example: "estimated cost"
pattern: |
[lemma=estimate] []? [lemma=cost]
- name: "estimate-opinion"
label: Cost
priority: 1
type: token
keep: false
example: "engineers opinion"
pattern: |
([lemma=engineer]|[lemma=budget]) [tag=POS]* []? ([lemma=opinion]|[lemma=estimate])
Note that the label for both estimated-cost and estimate-opinion is Cost. This allows us to reference either of them in a later rule.
- name: "engineers-estimate"
label: EngineersEstimate
priority: 2
pattern: |
trigger = @Cost
dollars:Dollars = (<nsubj|>nmod_of|>advcl)
This Event-Mention looks for our @Dollars regex that are nsubj, nmod_of, or advcl of any occurences of @Cost
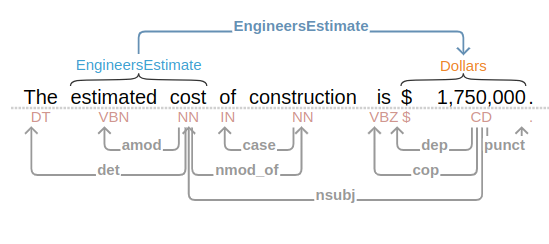
Engineer’s Estimate was one of the cleaner examples of these, I was able to capture all instances of the Estimate with one rule. Most other examples required a few rules to catch all the cases.
Example 2: Project Owner - Surface Capture
There were three different rules that were used to capture Project Owner, but the most successful was a surface-level rule that captured a string that occurred in the contract documents frequently.
The first part is a series of base rules for @Organization, attempting to capture the Companies, Municipalities, Counties, etc involved in these deals.
- name: "org-ner-basic"
label: Organization
type: token
priority: 1
keep: false
example: "Placer County Water Agency"
pattern: |
[entity=B-ORG] [entity=I-ORG]* [tag=NNP]?
- name: "org-surface-1"
label: Organization
type: token
priority: 1
keep: false
example: "Town of Windsor | County of Yolo | University of Arizona"
pattern: |
([lemma=city]|[lemma=town]|[lemma=university]|[lemma=county]) [lemma=of] [tag=NNP]
- name: "org-surface-2"
label: Organization
type: token
priority: 1
keep: false
example: "Tranquility Public Utility Districty | Yolo County"
pattern: |
[tag=NNP]{1,3} ([lemma=district]|[lemma=county]|[lemma=university])
Named Entity Recognition was only so successful at catching these, especially with strings containing regular English words like “Public Utility” or “Town of.” In the end, relatively hard-coded lemma rule was required to achieve consistent capture.
It took 7 rules to capture the project Owner across 12 sample documents.
- name: "owner-event-2"
label: ProjectOwner
priority: 3
example: "The Malaga County Water District is soliciting bids for ... "
pattern: |
trigger = [lemma=solicit] | [lemma=accept]
dummy_bid:Bid = >dobj
project_owner:Organization = >nsubj
- name: "owner-surface-3"
label: ProjectOwner
type: token
priority: 2
example: "Tranquility Public Utility District, hereinafter reffered to as owner"
pattern: |
@Organization (?=([]{0,3} ([lemma=refer]|[lemma=call]) []{0,3} @Owner))
The use of []{0,3} in owner-suface-3 matches any three tokens that occur in that spot.
This is an example output of that rule. 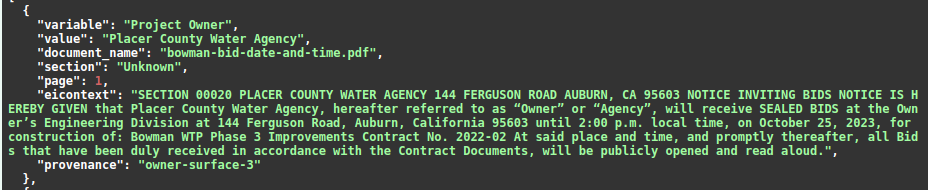
FILTERING AND SECTION GRAMMAR
Beyond just capturing these fields, we needed to present it to the customer in a digestible way. One of the drawbacks of my approach was that it might capture the Bid Date in several different locations in the document, so we needed to resolve that.
Another was that Project Duration was a particularly important field to the customer, but only the duration of the entire project. Typically smaller durations were included in the text in syntactically identical positions. I wrote a few functions for comparing these values in utils.py.
@staticmethod
def _filter_duplicate_extractions(
unfiltered_extractions: list[schema.Extraction],
) -> list[schema.Extraction]:
"""Removes duplicate extractions"""
# Filter for duplicate extractions
filtered_extractions = []
variable_value_pairs = set()
for ex in unfiltered_extractions:
if (ex.variable, ex.value) not in variable_value_pairs:
variable_value_pairs.add((ex.variable, ex.value))
filtered_extractions.append(ex)
return filtered_extractions
@staticmethod
def _duration_filter(
extractions: list[schema.Extraction],
) -> list[schema.Extraction]:
"""Returns the longest duration extraction"""
measure_duration = lambda ex: (float("".join(filter(str.isdigit, ex.value))))
max_duration = (-1, None)
for ex in extractions:
n = measure_duration(ex)
if n > max_duration[0]:
max_duration = (n, ex)
longest: schema.Extraction = max_duration[-1]
return longest
It was also important that should certain fields occur in an addendum, that they were flagged differently. This led to the creation of our section_grammar.yml.
To flag Addenda we applied section_grammar.yml to the processed text before applying variable grammar.yml. Then the API would call WMLUtils.section_determiner(), to populate a field called section: which the only valid labels for were Unknown and Addenda. This with the mention label were used to produce a final, end-user visible label from a schema not included in this documentation.
def section_determiner(mns: list[Mention]) -> str:
"""section_determiner checks to see what the earliest match is for our
section_grammar, presuming that a section name is likely to appear in the
header or title of a doc. If there is no match in the first 200 characters,
section-determiner returns "Unknown".
"""
if not mns:
return schema.SectionLabel.UNKNOWN
else:
# Looking at offsets
offset_dict = {}
for mn in mns:
offset_dict[mn.char_start_offset] = mn.label
key = min(offset_dict.keys())
if key <= 200:
return schema.SectionLabel.label_map(offset_dict[key])
else:
return schema.SectionLabel.UNKNOWN
Final Product
 The end result of the project was an API to which a PDF could be uploaded for processing and it would return a JSON like the following output for our file bowman-all-extractions.pdf.
The end result of the project was an API to which a PDF could be uploaded for processing and it would return a JSON like the following output for our file bowman-all-extractions.pdf.
[
{
"variable": "Project Owner",
"value": "Placer County Water Agency",
"document_name": "bowman-all-extractions.pdf",
"section": "Unknown",
"page": 1,
"html": null
},
{
"variable": "Project Owner",
"value": "Placer County Water Agency",
"document_name": "bowman-all-extractions.pdf",
"section": "Unknown",
"page": 1,
"html": null
},
{
"variable": "Bid Time",
"value": "2:00 p.m.",
"document_name": "bowman-all-extractions.pdf",
"section": "Unknown",
"page": 1,
"html": null
},
{
"variable": "Bid Date",
"value": "October 25, 2023",
"document_name": "bowman-all-extractions.pdf",
"section": "Unknown",
"page": 1,
"html": null
},
{
"variable": "Engineer's Estimate",
"value": "$1,750,ld 000",
"document_name": "bowman-all-extractions.pdf",
"section": "Unknown",
"page": 1,
"html": null
},
{
"variable": "Project Duration",
"value": "450",
"document_name": "bowman-all-extractions.pdf",
"section": "Unknown",
"page": 2,
"html": null
},
{
"variable": "Project Name",
"value": "Bowman WTP",
"document_name": "bowman-all-extractions.pdf",
"section": "Unknown",
"page": 5,
"html": null
},
{
"variable": "Project Location",
"value": "595 Christian Valley Rd,\nBowman, CA, 95602",
"document_name": "bowman-all-extractions.pdf",
"section": "Unknown",
"page": 6,
"html": null
}
]
Room for Improvement
While all the objectives for the internship were met, there is room for improvement in a couple of places.
Efficiency
Ultimately our system was relatively slow. It could take up to an hour to process one of the larger docs. This is especially nagging because our target extractions could typically be found in 5-10 pages of the docs. With a processing speed of around 4.5 seconds per page, it would be a lot nicer to only wait a minute rather than an hour.
Section-Aware Processing
Another issue was the risk of producing too many extractions. If we could work on identifying the portions of the document most likely to have our information, we could write syntactic rules that are more general, reducing the chance they would incorrectly match in the wrong section of the document. Getting page numbers involved might have had a significant impact, as the first 10 pages of each document often contained about half of our extractions. Ultimately that required changes to the pdf-reading system which was outside of the scope of the project.